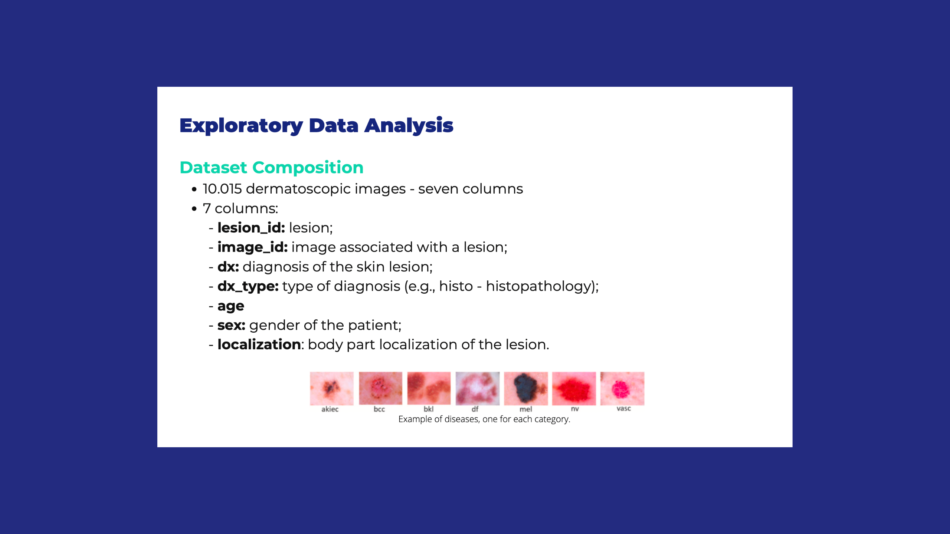
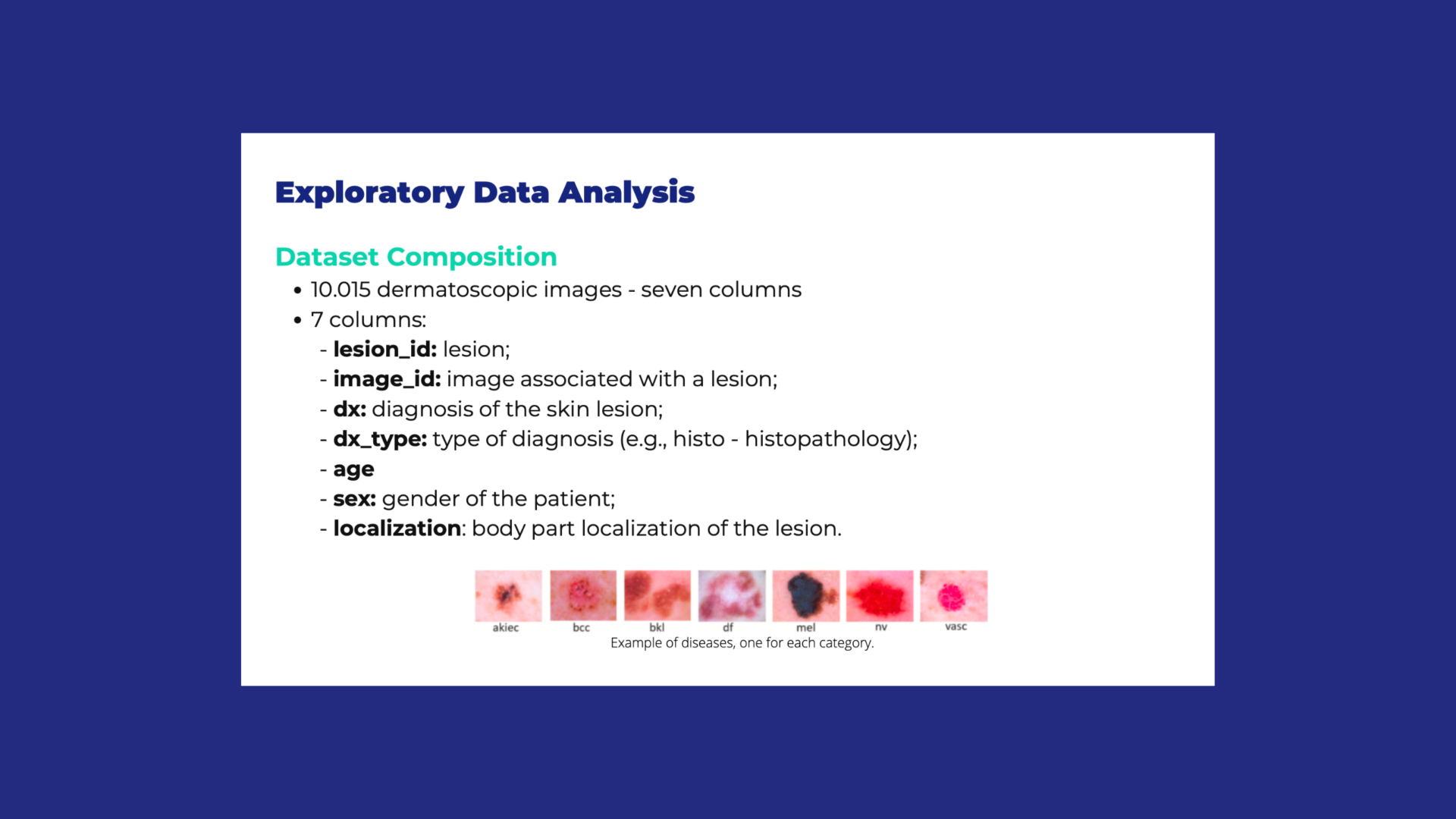
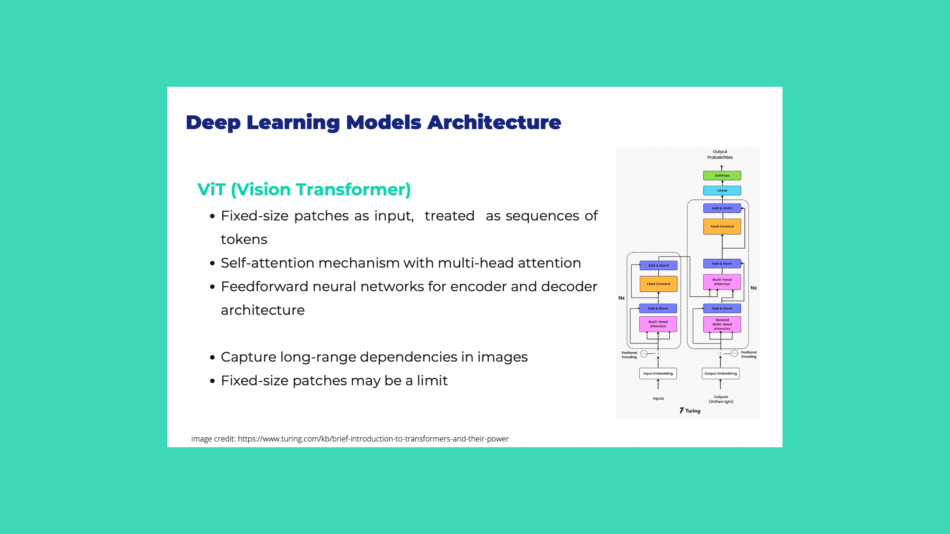
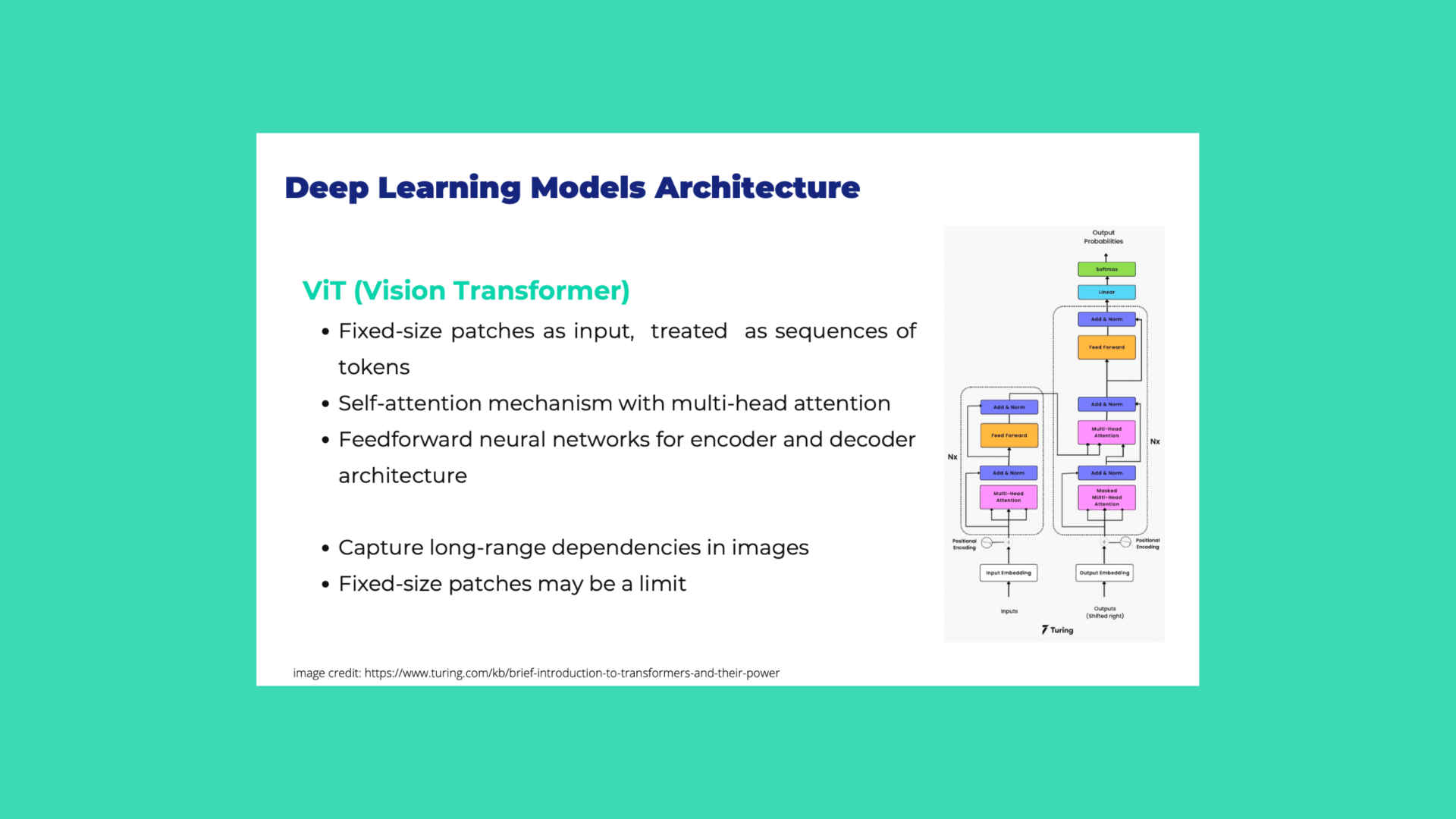
Abbiamo affrontato questa stimolante sfida di sviluppare un modello di intelligenza artificiale per l'identificazione e la classificazione delle lesioni cutanee, utilizzando le più recenti tecnologie di deep learning. Questo progetto ha richiesto l’integrazione di reti Vision Transformer (ViT), una delle architetture più avanzate nel campo della visione artificiale, per rendere il processo di diagnosi più rapido e preciso.
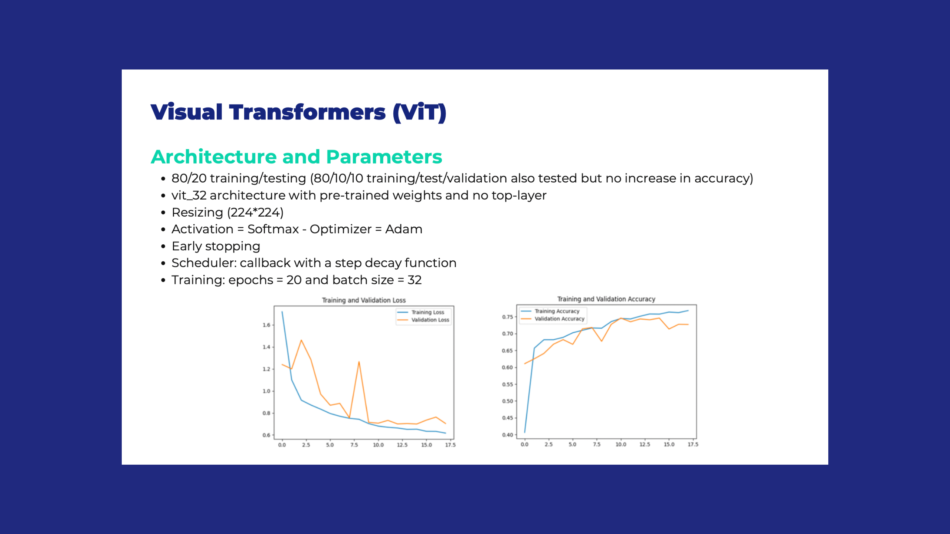
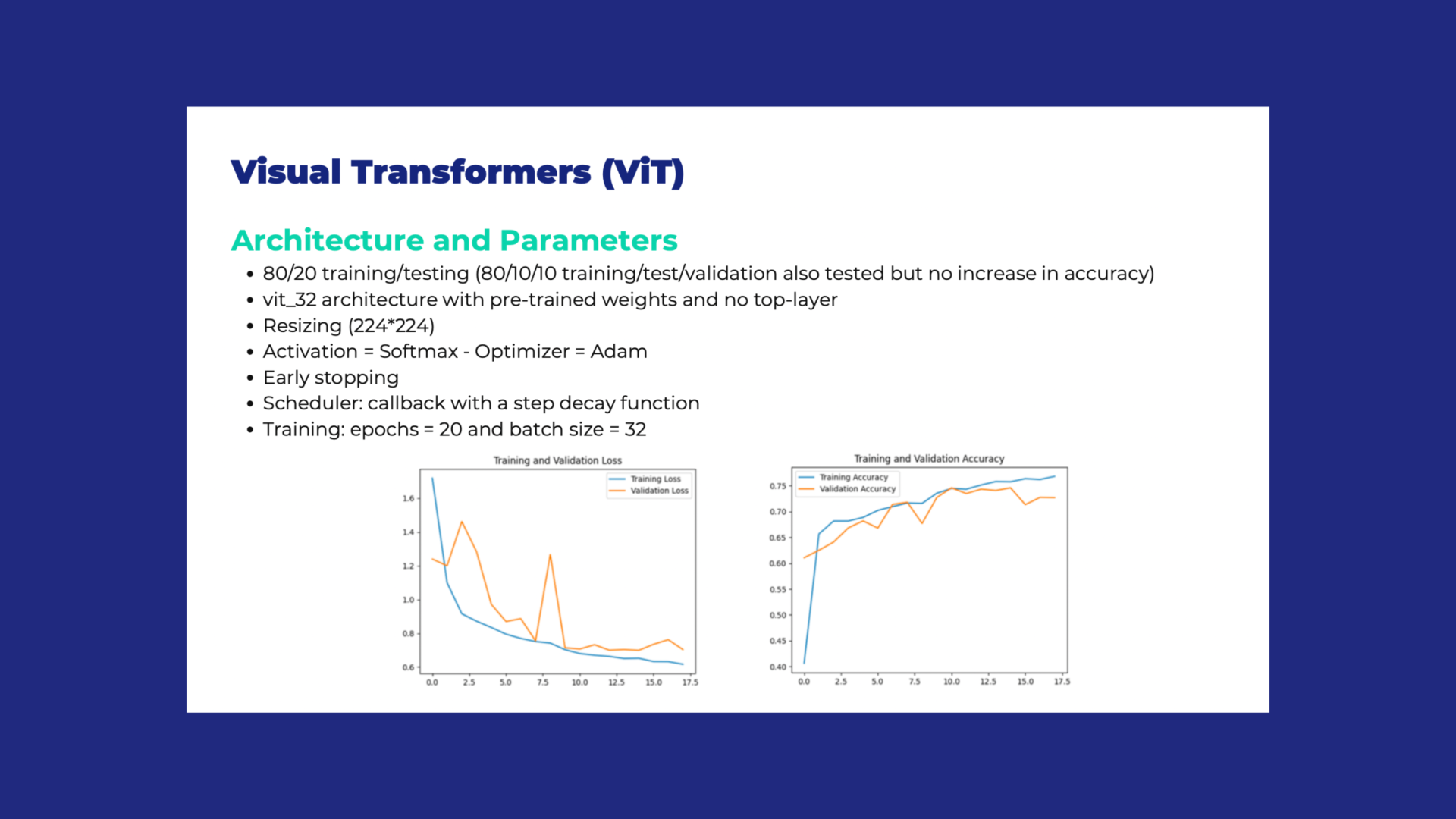
Da un punto di vista tecnico, i nostro modello è stato addestrato per riconoscere diverse tipologie di lesioni cutanee, garantendo un’elevata accuratezza grazie a tecniche di ottimizzazione avanzate come l’early stopping e il model checkpointing. Abbiamo applicato strategie per prevenire l’overfitting e migliorare le prestazioni, creando un sistema robusto e in grado di adattarsi a nuove sfide.
Questo progetto ha rappresentato un passo importante nella nostra esplorazione delle potenzialità dell’intelligenza artificiale in ambito medico, aprendoci a nuove possibilità per il futuro. Siamo orgogliosi dei risultati ottenuti e fiduciosi che, con ulteriori ottimizzazioni, il modello potrà fornire un supporto concreto ai professionisti della salute, migliorando la precisione nella diagnosi e contribuendo a una medicina più accessibile e personalizzata.